The Buyer Intelligence Advantage
How does buyer intelligence enhance Playbooks?
What Is Buyer Intelligence?
Buyer Intelligence is a powerful data drive tool to enhance your Playbooks experience. Many services use collective data to forecast behavior. For example, map applications use a collective body of reports from drivers to display live road conditions. Predicting buyer behavior is tricky because it depends on a variety of factors that are not immediately apparent from the information provided in your average CRM. Buyer Intelligence uses aggregated data to recommend the best strategy to engage buyers.
Buyer Intelligence Consists of 3 Main Parts
- Minor contributions from many individuals
- A system that enables mass collaboration to solve complex problems
- Optimized benefits for all users
How Do We Use Buyer Intelligence?
We use Buyer Intelligence to show our customers which tasks are likely to provide them with the maximum return for their investment of effort. We compile the results of activities that occur within our platform and apply machine learning to develop state of the art statistical models. We continually enhance these models and use them to provide our customers with the most helpful information available.
For example, a user may make a phone call to a number that is disconnected. We store the phone number and the outcome to warn other users not to invest time into dialing that disconnected number.
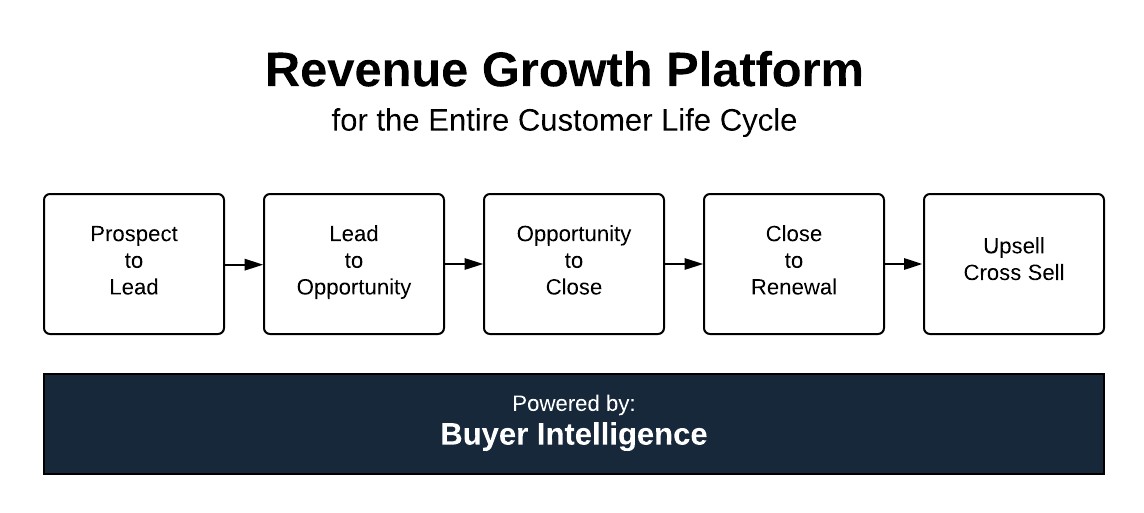
We use Buyer Intelligence to build solutions for every step of the customer revenue cycle (see chart below for customer revenue cycle details). Currently, we have several live solutions for the “Prospect to Lead”, “Lead to Opportunity”, and “Opportunity to Close” stages that are powered by Buyer Intelligence.
The customer revenue cycle can be represented by this five-step process:
What Playbooks Features Use Buyer Intelligence?
The following list shows features in Playbooks that leverage Buyer Intelligence. Each bullet is a link that will take you to an article where you can learn more about each feature.
